
ChannelSFormer: A Channel Agnostic Vision Transformer for Multi-Channel Cell Painting Images
Published in NeurIPS 2025 Workshop for Imageomics: Discovering Biological Knowledge from Images Using AI, 2025
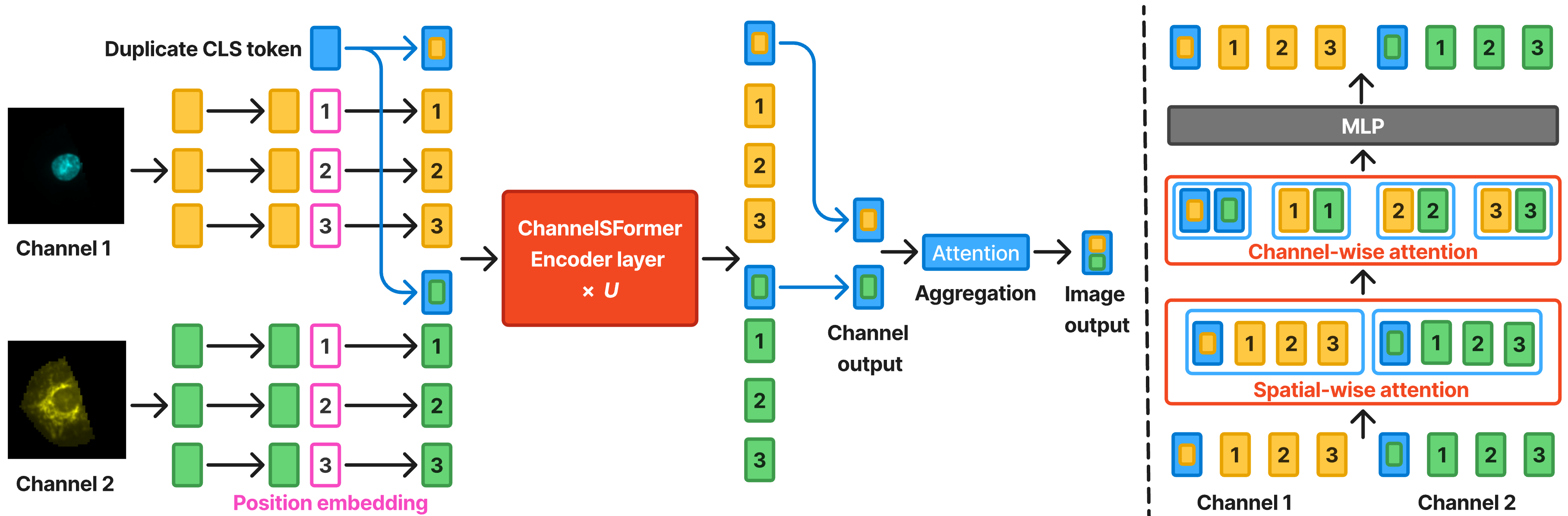
Abstract. High-content imaging using the Cell Painting assay is a cornerstone of modern drug discovery, generating multi-channel images where each channel reveals distinct cellular components. Existing Vision Transformers (ViTs) struggle with this data, as their global self-attention mechanisms are computationally expensive and become hard-coded to a specific number of channels, limiting flexibility. To address this, we introduce ChannelSFormer, a channel-agnostic Transformer architecture. ChannelSFormer decomposes the standard self-attention into two distinct steps: spatial-wise attention, which learns spatial relationship within each channel, and channel-wise attention, which learns relationships across channels. We also use per-channel class (CLS) token for each channel, which are duplicated from a single CLS token, to better capture per-channel information. ChannelSFormer eliminates the need for fixed channel embeddings, making the model adaptable to varying channels. Evaluation on the JUMP-CP dataset shows that ChannelSFormer surpasses SOTA methods by 4.12% - 7.58% in accuracy and is 27% - 281% faster.
More information are available at openreview, and GitHub.
Recommended citation: Jingwei Zhang, Srinivasan Sivanandan, "ChannelSFormer: A Channel Agnostic Vision Transformer for Multi-Channel Cell Painting Images", NeurIPS 2025 Workshop for Imageomics, 2025.
Download Paper